Qing Jiang (蒋擎)
Ph.D. Candidate @ South China University of Technology (SCUT)
Intern @ ByteDance Seed, BeiJing
Prev. Intern @ IDEA, ShenZhen
Email: mountchicken@outlook.com

Ph.D. Candidate @ South China University of Technology (SCUT)
Intern @ ByteDance Seed, BeiJing
Prev. Intern @ IDEA, ShenZhen
Email: mountchicken@outlook.com
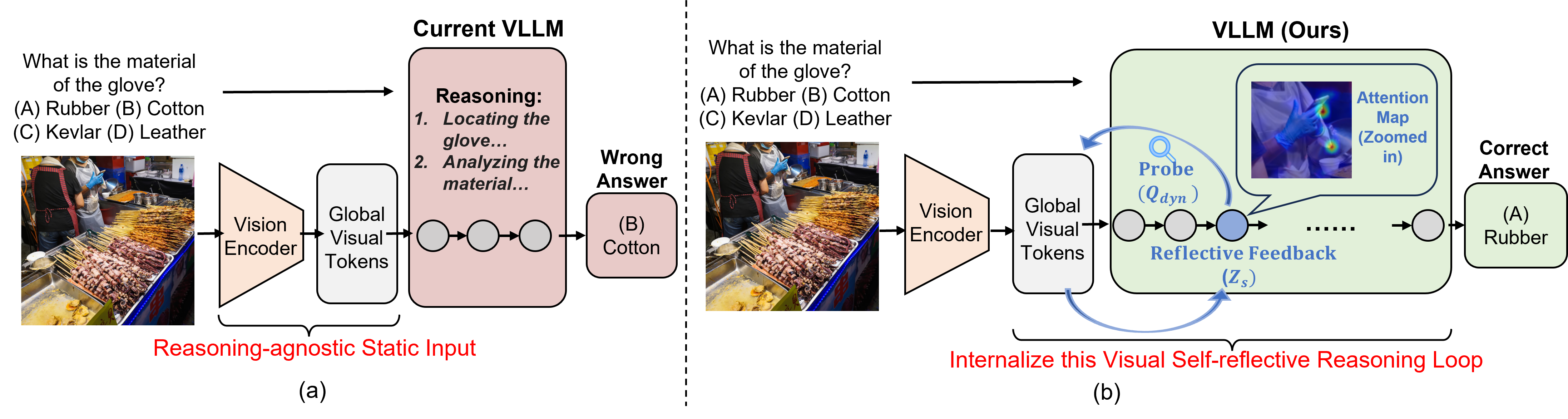
I am a fourth year Ph.D. candidate at SCUT, supervised by Prof. Lei Zhang. I am currently a research intern at ByteDance Seed, working on World Model. Previously, I interned at IDEA Research. My research interests lie in General Perception, World Model, and Embodied AI.
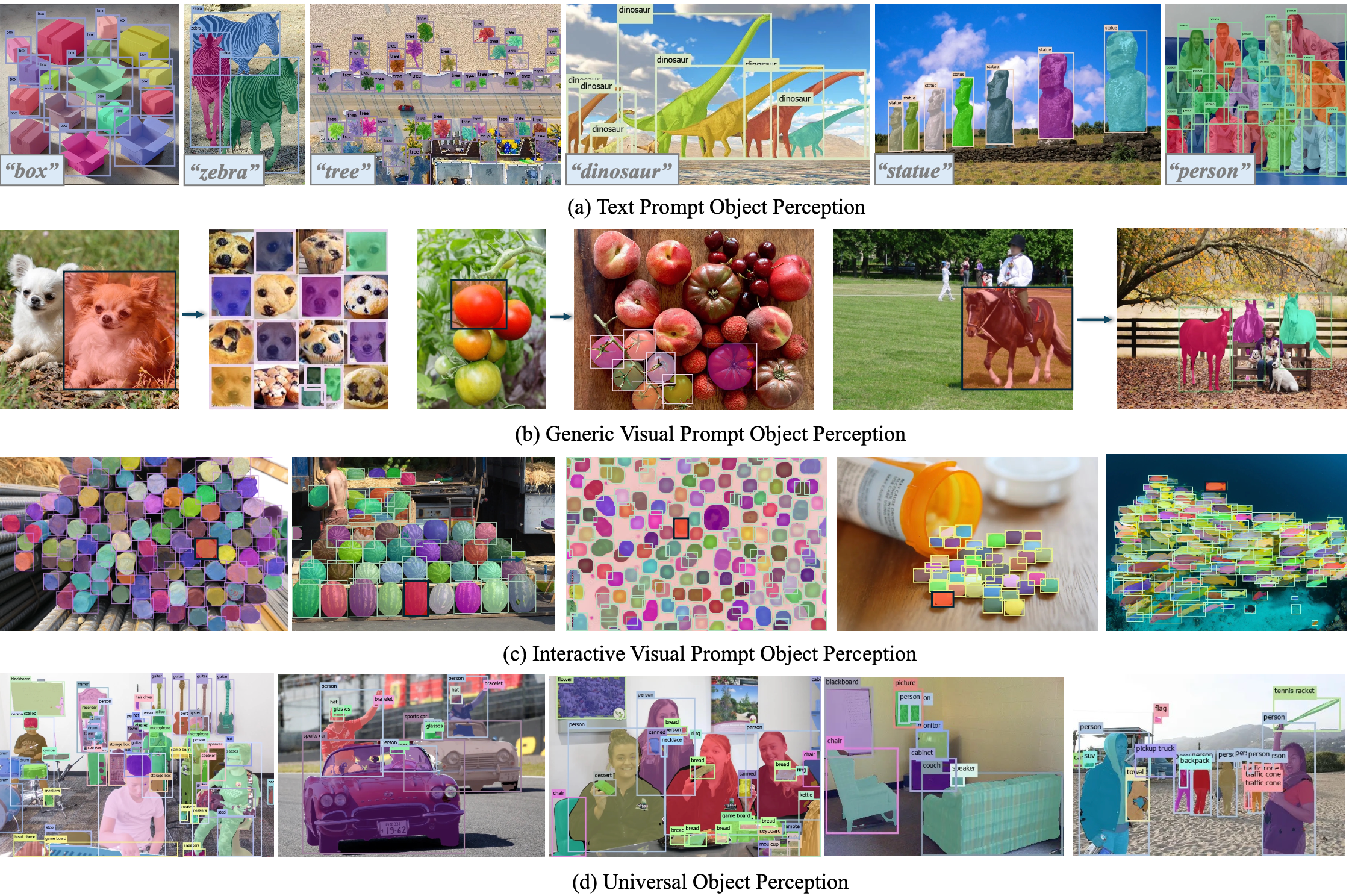
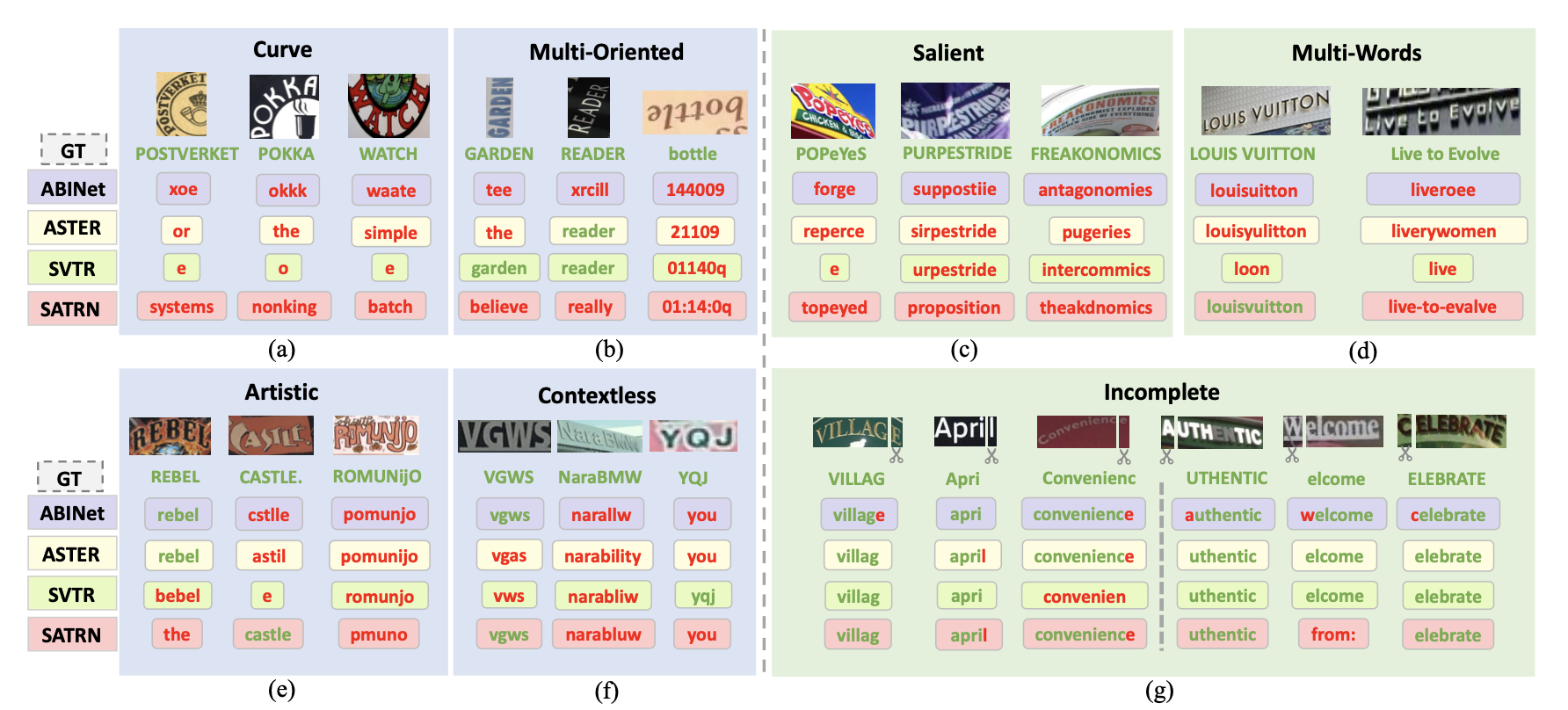
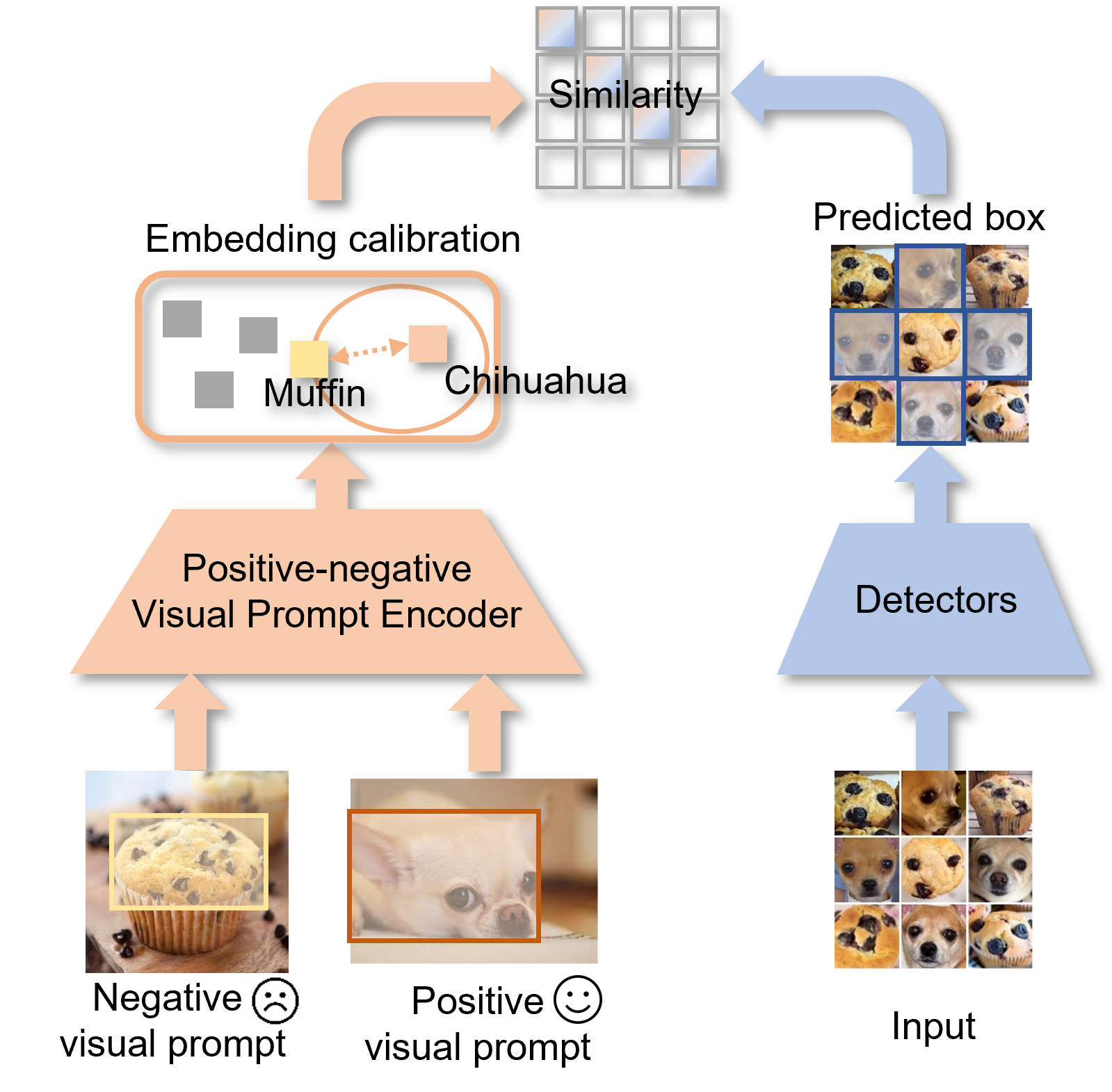
I have contributed to open-set object detection through text-prompted models (Grounding DINO 1.5), visual-prompted models (T-Rex, T-Rex2), the unified model DINO-X, and MLLM-based approaches (ChatRex, RexSeek, Rex-Thinker, Rex-Omni). I also maintain open-source projects including Resophy, MMOCR, and Scene Text Recognition Recommendations.










| ByteDance Seed | Research Intern | 2026.04 – now |
| International Digital Economy Academy (IDEA) | Research Intern | 2023.06 – 2026.03 |
| Shanghai AI Lab (OpenMMLab) | Intern | 2022.02 – 2022.08 |